| INNOV.RU | Информационный портал |
Формирование языка запросов для системы поддержки принятия решений
Formation of the query language for decision support system
УДК 004.434
Выходные сведения: Назаров Р.Э., Филатов А.В., Харченко Е.А., Храмов И.С. Формирование языка запросов для системы поддержки принятия решений // Иннов: электронный научный журнал, 2018. №7 (40). URL: http://www.innov.ru/science/tech/formirovanie-yazyka-zaprosov-dlya-s/
Авторы:
Назаров Р.Э.1, Филатов А.В.2, Харченко Е.А.3, Храмов И.С.4
1 бакалавр, направление «Информатика и вычислительная техника», Московский политехнический университет, Москва, Российская Федерация (107023, г. Москва, ул. Б. Семеновская, 38), e-mail: nazarovrbox@mail.ru
2 бакалавр, направление «Информатика и вычислительная техника», Московский политехнический университет, Москва, Российская Федерация (107023, г. Москва, ул. Б. Семеновская, 38), e-mail: afilatov5@mail.ru
3 старший преподаватель кафедры «Прикладная информатика», Московский политехнический университет, Москва, Российская Федерация (107023, г. Москва, ул. Б. Семеновская, 38), e-mail: elenakhaa@gmail.com
4бакалавр, направление «Информатика и вычислительная техника», Московский политехнический университет, Москва, Российская Федерация (107023, г. Москва, ул. Б. Семеновская, 38), e-mail: main@ikhramov.me
Authors:
Nazarov R.E.1, Filatov A.V.2, Kharchenko E.A.3, Khramov I.S.4
1 bachelor, specialty «Informatics and computer systems», Moscow Polytechnic University, Moscow, Russian Federation (107023, Moscow, Bolshaya Semenovskay st., 38), e-mail: nazarovrbox@mail.ru
2 bachelor, specialty «Informatics and computer systems», Moscow Polytechnic University, Moscow, Russian Federation (107023, Moscow, Bolshaya Semenovskay st., 38), e-mail: afilatov5@mail.ru
3 senior lecturer of department «Applied Informatics», Moscow Polytechnic University, Moscow, Russian Federation (107023, Moscow, Bolshaya Semenovskay st., 38), e-mail: elenakhaa@gmail.com
4 bachelor, specialty «Informatics and computer systems», Moscow Polytechnic University, Moscow, Russian Federation (107023, Moscow, Bolshaya Semenovskay st., 38), e-mail: main@ikhramov.me
Ключевые слова: система поддержки принятия решений, формальные языки, проблемно-ориентированные языки, контекстно-свободная грамматика, лексический анализатор, синтаксический анализатор, ANTLR
Keyword: decision support system, formal language, domain specific language, context-free grammar, lexer, parser, ANTLR
Annotation: This article considers the effective way for formation of internal query language for some decision support system, in which the solution is produced by one of the universal methods of expert estimates. The primary solution is presented by a set of alternative solutions. Each alternative solution is a set of values of indicators that characterize the problem under study. Moreover, qualitative and quantitative indicators are processed uniformly and simultaneously. Each alternative solution is identified with a binary vector, which simplifies pairwise comparison of solutions. The expediency of developing a special language tool is explained by the need to study specific data to make a final decision. In the considered language are contained universal logical constructions that are in demand when formalizing the requirements for any data. To develop a query language interpreter is proposed to use a powerful parser generator ANTLR. The procedure for specifying a specific query language by context-free grammar is described. Also describes the procedure to generate the parser, lexer and files intended for bypass of parse trees. Java is considered as the target programming language. The main methods of use and modification of the obtained classes are described. They can be embedded in a problem information system to manipulate specific data. The modern areas of applied application of theoretical and practical mechanisms for creating language software tools are described.

Введение
Естественным сопровождением управленческой и производственной деятельности современных организаций является функционирование корпоративных и индустриальных информационных систем. В них явно аккумулируются большие объемы информации о параметрах объектов рабочей предметной области и связях между ними. Также в накопленных данных могут присутствовать многосложные скрытые связи, недоступные для непосредственного человеческого восприятия, но несущие в себе дополнительные знания о предметной области. Для их обнаружения с целью повышения эффективности принимаемых решений прибегают к методам интеллектуального анализа данных (англ. data mining) [4, 5, 9, 13, 15, 16].
Первичную обработку больших данных (англ. big data) с выделением полезной информации зачастую доверяют специальным системам поддержки принятия решений (СППР) (англ. Decision Support System, DSS). Такие системы не вырабатывают автоматически окончательные решения, их основная задача – представить извлеченную информацию в адаптированном для аналитика виде и предоставить инструменты для проведения аналитиком исследовательской работы [4]. При этом особенно важно обеспечить аналитику достаточную свободу в формировании запросов к данным. Приведем пример, иллюстрирующий целесообразность построения внутреннего миниатюрного языка запросов для интерактивной СППР.
Сегодня принятие обоснованных управленческих и производственных решений усложняется условиями рыночной экономики и глобальной технологической неопределенностью [1, 7]. Для поиска решений в ситуации нехватки объективных знаний о предметной области широко распространены методы экспертных оценок. Суть методов экспертных оценок заключается в выявлении «общественного мнения» в отношении значений параметров, характеризующих изучаемую проблему. Как правило, вырабатывается сразу несколько альтернативных решений (областей согласованных мнений экспертов). Чтобы предпочесть одно из них в качестве окончательного решения, исследователь должен иметь возможность манипулировать «черновыми» решениями – сравнивать между собой, проверять происхождение и изучать структуру [9].
Если унифицировать способ представления количественных и качественных показателей [9], то первичные решения, автоматически выработанные СППР, могут быть описаны характеристическим логическим уравнением, заданным в совершенной дизъюнктивной нормальной форме (СДНФ), например (для трех решений):
![]()
здесь значение 1 (true) переменной означает присутствие в решении строго определенного признака, значение 0 (false) – его отсутствие. СДНФ, очевидно, упрощает непосредственное вычисление сгенерированной формулы.
При изучении или отборе полученных альтернативных решений на значения отдельных двоичных переменных исследователем могут быть наложены дополнительные ограничения. Алгебра логики позволяет формализовывать и выражать их в недвусмысленной, допускающей только однозначное толкование, форме [6]. Например, требования «должны одновременно присутствовать второй и четвертый признаки» и «если одновременно присутствуют первый и пятый признаки, то должен отсутствовать третий признак» могут быть описаны логическими уравнениями:
![]()
и
![]()
соответственно. Тогда из решений исходной задачи отбираются лишь те, которые удовлетворяют дополнительным уравнениям: первому ограничению отвечает третий дизъюнктивный член первичного решения, а второму – второй.
Чтобы обеспечить возможность пользователю-исследователю сообщать системе формализованные требования к решению, необходимо составить внутренний язык запросов, учитывающий специфику представления данных в конкретной СППР [4], и обучить систему распознавать инструкции на этом языке. Математические аспекты создания языка предметной области (англ. Domain Specific Language, DSL) освещает теория формальных языков [8, 14]. Облегчить же оперативную программную разработку лексических и синтаксических анализаторов призваны генераторы формальных языков, самым популярным представителем которых в настоящее время является ANTLR (от англ. ANother Tool for Language Recognition, «еще одно средство распознавания языков») [17, 20, 21].
Материалы и методы
Для наглядного задания бесконечных формальных языков, т.е. все строки которых невозможно перечислить, зачастую используют грамматики. Под грамматикой понимают «четверку»
![]()
состоящую из множества нетерминальных (заменяемых) символов, множества терминальных (алфавитных) символов, множества продукций (правил) и стартового нетерминального символа соответственно [2, 3, 11].
Грамматика генерирует последовательности терминальных символов, составляющих строки языка. Процедура формирования очередной строки начинается с продукции, содержащей стартовый символ в левой части. Нетерминалы из правой части продукции последовательно заменяются на определяемые правилами грамматики наборы символов (разных типов в общем случае). Вывод строки завершается после получения последовательности, содержащей только терминалы. За принадлежащие языку принимают те, и только те строки, которые можно получить посредством заданной грамматики, т.е. грамматика не должна пропускать «недопустимые» строки.
В основе лексического анализа, как правило, лежат регулярные грамматики (их можно заменить регулярными выражениями) – правосторонние или левосторонние. В правосторонних грамматиках каждая продукция имеет вид (отсутствует средняя рекурсия):
![]()
или
![]()
где
![]()
В левосторонних грамматиках цепочки разрастаются в левую сторону (продукции могут содержать только левую рекурсию).
Для синтаксического анализа необходимы контекстно-свободные грамматики, в них продукции имеют вид (может содержаться средняя рекурсия):
![]()
где
![]()
Согласно классификации Хомского, регулярные языки являются подмножеством контекстно-свободных [2, 3, 11]. В левых частях продукций свободных от контекста грамматик присутствует ровно один нетерминал, без окружения.
Какой бы ни была специфика конкретной системы поддержки принятия решений, во внедряемый в нее язык запросов необходимо включить модифицированный язык предикатов как универсальный формат формализации утверждений [6]. Аналитик имеет потребность вводить запросы в компактном виде, поэтому, кроме основных логических операций (конъюнкции, дизъюнкции и отрицания), в языке уместны и производные логические операции (импликация и эквивалентность) с ограничением многовложенности. Для большей лаконичности и явного обозначения причинно-следственных связей между логическими конструкциями запроса в язык также целесообразно добавить облегченные операторы ветвления (if, if-else).
Разработка «с нуля» программных средств разбора профильных текстов, т.е. синтаксических анализаторов, крайне трудоемка, во многом ее может упростить использование специализированного программного инструментария [17, 20, 21]. Так ANTLR 4 по g4-файлу с описанием контекстно-свободной грамматики в расширенной форме Бэкуса-Наура (РБНФ) автоматически генерирует лексический и синтаксический анализаторы. Лексический анализатор, или лексер (англ. lexer), предназначен для выделения в потоке входных символов лексических единиц (лексем), или токенов (англ. tokens), а синтаксический анализатор, или парсер (англ. parser), предназначен для проверки корректности расположения лексем относительно друг друга в потоке лексем.
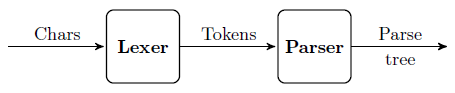
В ANTLR нет необходимости разделять описания грамматик для лексера и парсера: синтаксические правила должны декларироваться прежде лексических. Ниже представлено синтаксические правила, описывающие построение выражения-запроса для рассматриваемой интеллектуальной системы (названия терминалов записаны прописными буквами, нетерминалов – строчными).

В описаниях правил грамматики допустимы, но нежелательны, включения java-кода для выполнения семантических действий (в том числе описания возвращаемых значений) при непосредственном разборе правил.
В качестве примеров лексических правил приведем описания названий логических переменных и операции импликации.

Каждому заявленному подобным образом токену (ключевому слову, оператору и др.) присваивается идентификатор. Следует избегать назначения токенами незначимых для разбора последовательностей символов – самостоятельных (например, пробелов) или фрагментов значимых последовательностей (например, числовых последовательностей в названиях переменных).
Упростить разработку грамматики может специализированная среда ANTLRWorks2: в ней сразу, на этапе редактирования, обнаруживаются синтаксические ошибки кода, описывающего грамматику, и конфликтующие правила грамматики, а также каждое правило визуализируется синтаксической диаграммой.
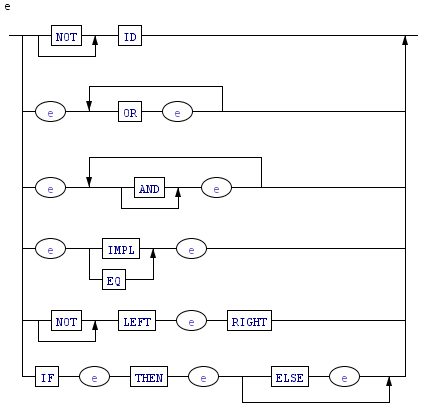
ANTLR реализует стратегию нисходящего синтаксического анализа и работает с «естественным» классом грамматик – LL-грамматиками: вход читается слева (left) направо и выдается левый (left) разбор. LL-грамматики – это подмножество контекстно-свободных грамматик, для которых детерминированность разбора достигается простым приемом: анализатор на входе заглядывает на несколько символов вперед и делает очередной шаг на основе того, что видит [2, 3, 11].
Результаты и обсуждение
Итак, NTLR позволяет по описанию грамматики создавать парсер на одном из целевых языков программирования (Java, C#, Python, JavaScript, Go, C++ и Swift), который может быть интегрирован в прикладное программное обеспечение для распознавания и разбора цепочек предметно-ориентированных языков. Сам же генератор NTLR написан на языке Java. Актуальной и поддерживаемой версией ANTLR является четвертая, официальный сайт проекта – http:// www. antlr.org. Для определенности в качестве целевого языка программирования выберем Java, крайне востребованного при разработке защищенных информационных систем [10, 12].
Перед началом работы необходимо загрузить jar-библиотеки совместимых версий: complete – для генерации java-файлов анализаторов, runtime – для их компиляции. Чтобы инициировать генерацию лексера и парсера по предварительно подготовленному файлу грамматики необходимо выполнить, команду следующего вида:
![]()
В отсутствие ошибок ее завершение приведет к образованию отдельной директории со сгенерированными служебными файлами и java-файлами (дальше будем опускать проектную приставку DSS в названиях файлов):

Видно, что коды классов лексера и парсера находятся в разных файлах. Сформированные по грамматике токены также описаны в отдельном файле.
По входному потоку символов создается экземпляр класса Lexer, по нему формируется буфер токенов, по которому создается экземпляр класса Parser (в привнесенном базовом классе). Парсер принимает входную цепочку символов и строит дерево разбора (англ. parse tree), обход которого средствами ANTLR осуществим разными способами [17, 21].

По умолчанию для обхода дерева разбора предусмотрен механизм Listener, альтернативой ему является Visitor. Отказаться от первого в пользу последнего возможно, добавив в команду генерации анализаторов ключи:
![]()
Выбор, главным образом, состоит в тотальном или выборочном обходе узлов дерева разбора. Каждый подход имеет свои преимущества.
В Listener методы посещения всех потомков вызываются автоматически, а в Visitor при обработке потомков любого узла необходимо вручную вызывать методы их обхода. Кроме того, методы Listener не могут возвращать значения, методы Visitor – могут. Ниже представлен пример обработки посещения узла, соответствующего токену логической переменной, в автоматически сгенерированном классе BaseListener, реализующем интерфейс Listener.
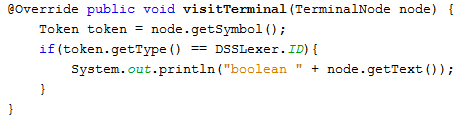
Работая с Visitor, нет необходимости хранить информацию о посещенных узлах, в Listener же приходится использовать вспомогательные переменные.
Проиллюстрируем работу описанного парсера примерами трех запросов, характерных для представленной выше проблемной области.

Ввод каждого запроса сопровождается построением и выводом в текстовом варианте дерева разбора. Ниже представлена графическая интерпретация дерева разбора второго запроса.

Сообщение об ошибке выводится в случае, когда введенная цепочка распознается как недопустимая для данного языка.
Выводы
Изложенный в статье материал дает комплексное представление об эффективном и современном способе формирования специального языка запросов для предметной информационной системы. В качестве примера приводится система поддержки принятия решений, в которой многомерные данные представляются в простой и наглядной форме – в виде двоичного вектора (единица означает присутствие признака в решении, ноль – его отсутствие) [9, 18, 19]. Языки запросов характерны тем, что содержат в себе универсальные логические конструкции для описания предикатов [6], что привносит иллюстративность в описанную методику и делает ее преемственной при решении подобных задач.
Разработка же программных средств распознавания и интерпретации строк формальных языков требует глубоких специальных знаний – как теоретических, так и практических. Свести к минимуму время подготовки и реализации языковых инструментов позволяет специализированное программное обеспечение, как, например, хорошо зарекомендовавший себя генератор анализаторов формальных языков ANTLR [17, 21]. Получаемый в результате его применения программный код имеет лаконичную и организованную структуру, благодаря чему легко поддается модификации и интеграции в прикладные программные решения.
Технологии оперативной разработки интерпретаторов предметно-ориентированных языков особенно востребованы при разработке информационных систем, предназначенных для работы с большими данными. Анализ таких данных позволяет получать неявные многоуровневые виртуальные образы пользователей, товаров, услуг, технологических процессов и др., своевременное и компетентное толкование которых (с привлечением узких специалистов) может способствовать повышению эффективности работы организации любого профиля (главным образом, созданием более совершенных моделей оперируемых объектов). В методах же обработки больших данных зачастую заложены алгоритмы кластеризации и классификации, под которые легко адаптируются многие методы экспертных оценок [5, 9]. Чрезвычайно актуализирует проблему интерпретации полезной информации, извлеченной из больших данных, повсеместное использование интернета вещей (англ. Internet of Things, IoT) [15, 16].
1. Асмолов А.Г. Психология современности: вызовы неопределенности, сложности и разнообразия. // Психологические исследования. – 2015. – Т. 8. – № 40. – URL: http://www.psystudy.ru/num/2015v8n40/1109
2. Ахо А., Лам М., Сети Р., Ульман Дж. Компиляторы. Принципы, технологии и инструментарий. – М.: Вильямс, 2016. – 1184 с.
3. Ахо А., Ульман Дж. Компиляторы. Теория синтаксического анализа, перевода и компиляции. Синтаксический анализ. – М.: Мир, 1972. – 612 с.
4. Барсагян А.А. Анализ данных и процессов. – СПб.: БХВ-Петербург, 2009. – 512 с.
5. Бериков В.Б., Лбов Г.С. Современные тенденции в кластерном анализе. –2009. – 26 с. – URL: http://www.ict.edu.ru/ft/005638/62315e1-st02.pdf
6. Грис Д. Наука программирования. – М.: Мир, 1984. – 416 с.
7. Клячко Т.Л., Мау В.А. Будущее университетов. – М.: Издательский дом «Дело» РАНХиГС, 2015. – 64 с.
8. Фаулер М. Предметно-ориентированные языки программирования. – М.: Вильямс, 2011. – 576 с.
9. Харченко А.А., Харченко Е.А. Потенциальная схема адаптации образовательных программ инженерных специальностей под потребности предприятий-работодателей // Известия МГИУ. Информационные технологии и моделирование. – М., 2012. – № 3(27) – С. 62-73.
10. Хеффельфингер Д. Java EE и сервер приложений GlassFish 4. – М.: ДМК Пресс, 2016. – 332 с.
11. Хопкрофт Дж., Мотвани Р., Ульман Дж. Введение в теорию автоматов, языков и вычислений. – М.: Вильямс, 2016. – 528 с.
12. Чипига А.Ф. Информационная безопасность автоматизированных систем. – М.: Гелиос АРВ, 2010. – 336 с.
13. Шелухин О.Н., Сакалема Д.Ж., Филинова А.С. Обнаружение вторжений в компьютерные сети (сетевые аномалии). – М.: Горячая линия-Телеком, 2016. – 220 с.
14. Barkol O., Lehavi D. The NFA Segments Scan Algorithm. – HP Laboratoris, 2014. – 13 с.
15. Filonov P., Kitashov F., Lavrentyev A. RNN-based Early Cyber-Attack Detection for the Tennessee Eastman Process. – 2017. – 5 с. – URL: https://arxiv.org/pdf/1709.02232.pdf
16. Filonov P., Lavrentyev A., Vorontsov A. Multivariate Industrial Time Series with Cyber-Attack Simulation: Fault Detection Using an LSTM-based Predictive Data Model. – 2016. – 8 с. – URL: https://arxiv.org/pdf/1612.06676.pdf
17. Parr T. The Definitive ANTLR 4 Reference. – The Pragmatic Bookshelf, 2013. – 322 с.
18. Ritchey T. General Morphological Analysis. A general method for non-quantified modelling. – 2013. – 10 с. – URL: http://www.swemorph.com/pdf/gma.pdf
19. Ritchey T. General Morphological Analysis as a basic scientific modelling method. – 2018. – 17 с. – URL: http://www.swemorph.com/pdf/tfsc-pre-gma.pdf
20. Underwood W., Laib S. Attribute Grammars and Parsers for Chunk-based Binary File Formats. – 2012. – 78 с. – URL: http://perpos.gtri.gatech.edu/publications/TR_12-01-Attribute_Grammars_and_Parsers_for_Chunk-based_File_Formats.pdf
21. http://www.antlr.org – официальный сайт пректа ANTLR v.4 (дата последнего обращения 25.06.2018)
1. Asmolov A.G. Psihologiya sovremennosti: vyzovy neopredelennosti, slozhnosti i raznoobraziya. Psihologicheskie issledovaniya. 2015. T. 8. No 40. URL: http://www.psystudy.ru/num/2015v8n40/1109
2. Aho A., Lam M., Seti R., Ul'man Dzh. Kompilyatory. Principy, tekhnologii i instrumentarij. M.: Vil'yams, 2016. 1184 p.
3. Aho A., Ul'man Dzh. Kompilyatory. Teoriya sintaksicheskogo analiza, perevoda i kompilyacii. Sintaksicheskij analiz. M.: Mir, 1972. 612 p.
4. Barsagyan A.A. Analiz dannyh i processov. SPb.: BHV-Peterburg, 2009. 512 p.
5. Berikov V.B., Lbov G.S. Sovremennye tendencii v klasternom analize. 2009. 26 p. URL: http://www.ict.edu.ru/ft/005638/62315e1-st02.pdf
6. Gris D. Nauka programmirovaniya. M.: Mir, 1984. 416 p.
7. Klyachko T.L., Mau V.A. Budushchee universitetov. M.: Izdatel'skij dom «Delo» RANHiGS, 2015. 64 p.
8. Fauler M. Predmetno-orientirovannye yazyki programmirovaniya. M.: Vil'yams, 2011. 576 p.
9. Harchenko A.A., Harchenko E.A. Potencial'naya skhema adaptacii obrazovatel'nyh programm inzhenernyh special'nostej pod potrebnosti predpriyatij-rabotodatelej. Izvestiya MGIU. Informacionnye tekhnologii i modelirovanie. M., 2012. No 3(27). Pp. 62-73.
10. Heffel'finger D. Java EE i server prilozhenij GlassFish 4. M.: DMK Press, 2016. 332 p.
11. Hopkroft Dzh., Motvani R., Ul'man Dzh. Vvedenie v teoriyu avtomatov, yazykov i vychislenij. M.: Vil'yams, 2016. 528 p.
12. Chipiga A.F. Informacionnaya bezopasnost' avtomatizirovannyh sistem. M.: Gelios ARV, 2010. 336 p.
13. Heluhin O.N., Sakalema D.ZH., Filinova A.S. Obnaruzhenie vtorzhenij v komp'yuternye seti (setevye anomalii). M.: Goryachaya liniya-Telekom, 2016. 220 p.
14. Barkol O., Lehavi D. The NFA Segments Scan Algorithm. HP Laboratoris, 2014. 13 p.
15. Filonov P., Kitashov F., Lavrentyev A. RNN-based Early Cyber-Attack Detection for the Tennessee Eastman Process. 2017. 5 p. URL: https://arxiv.org/pdf/1709.02232.pdf
16. Filonov P., Lavrentyev A., Vorontsov A. Multivariate Industrial Time Series with Cyber-Attack Simulation: Fault Detection Using an LSTM-based Predictive Data Model. 2016. 8 p. URL: https://arxiv.org/pdf/1612.06676.pdf
17. Parr T. The Definitive ANTLR 4 Reference. The Pragmatic Bookshelf, 2013. 322 p.
18. Ritchey T. General Morphological Analysis. A general method for non-quantified modelling. 2013. 10 p. URL: http://www.swemorph.com/pdf/gma.pdf
19. Ritchey T. General Morphological Analysis as a basic scientific modelling method. 2018. 17 p. URL: http://www.swemorph.com/pdf/tfsc-pre-gma.pdf
20. Underwood W., Laib S. Attribute Grammars and Parsers for Chunk-based Binary File Formats. 2012. 78 p. URL: http://perpos.gtri.gatech.edu/publications/TR_12-01-Attribute_Grammars_and_Parsers_for_Chunk-based_File_Formats.pdf
21. http://www.antlr.org – oficial'nyj sajt prekta ANTLR v.4 (data poslednego obrashcheniya 25.06.2018)
архив: 2013 2012 2011 1999-2011 новости ИТ гость портала 2013 тема недели 2013 поздравления
E-mail редакции: vzh85@yandex.ru, 