| INNOV.RU | Информационный портал |
Разработка вопросно-ответной системы с нейросетевым обучением на базе современных свободных технологий
Design of Question Answering System Based on Neural Networks and Modern Free Technologies
Выходные сведения: Науменко А.М., Шелудько С.Д., Юлдашев Р.Ю., Хлебников Н.О., Радыгин В.Ю. Разработка вопросно-ответной системы с нейросетевым обучением на базе современных свободных технологий // Иннов: электронный научный журнал, 2017. №2 (31). URL: http://www.innov.ru/science/tech/razrabotka-voprosno-otvetnoy-sistem/
Авторы:
Науменко А.М.1, Шелудько С.Д.2, Юлдашев Р.Ю. 3, Хлебников Н.О. 4, Радыгин В.Ю.5
1 студент 4-го курса бакалавриата по направлению «Информационные системы и технологии», ФГАОУ ВО Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация (115409, г. Москва, Каширское ш., 31), e-mail: naumenko.mephi@gmail.com.
2 студент 4-го курса бакалавриата по направлению «Информационные системы и технологии», ФГАОУ ВО Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация (115409, г. Москва, Каширское ш., 31), e-mail: sheludko.serg@gmail.com.
3 студент 4-го курса бакалавриата по направлению «Информационные системы и технологии», ФГАОУ ВО Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация (115409, г. Москва, Каширское ш., 31), e-mail: romanyuldashev@gmail.com.
4 студент 4-го курса бакалавриата по направлению «Информационные системы и технологии», ФГАОУ ВО Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация (115409, г. Москва, Каширское ш., 31), e-mail: nikolay.khlebnikoff@gmail.com.
5 к.т.н., доцент кафедры финансового мониторинга, ФГАОУ ВО Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация (115409, г. Москва, Каширское ш., 31), e-mail: vyradygin@mephi.ru.
Authors:
Naumenko A.M.1, Sheludko S.D.2, Uldashev R.Yu. 3, Hlebnikov N.O. 4, Radygin V.Yu.5
1 fourth year BA-student, specialty “Information systems and technologies”, National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation (115409, Moscow, Kashirskoe shosse, 31), e-mail: naumenko.mephi@gmail.com.
2 fourth year BA-student, specialty “Information systems and technologies”, National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation (115409, Moscow, Kashirskoe shosse, 31), e-mail:
sheludko.serg@gmail.com.
3 fourth year BA-student, specialty “Information systems and technologies”, National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation (115409, Moscow, Kashirskoe shosse, 31), e-mail: romanyuldashev@gmail.com.
4 fourth year BA-student, specialty “Information systems and technologies”, National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation (115409, Moscow, Kashirskoe shosse, 31), e-mail: nikolay.khlebnikoff@gmail.com.
5 Ph.D., assistant professor of dept. Financial Monitoring, National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation (115409, Moscow, Kashirskoe shosse, 31), e-mail: vyradygin@mephi.ru.
Ключевые слова: машинное обучение, вопросно-ответная система, синтаксическое дерево, word2vec, nltk, pymorphy2, python, нейросетевой анализ данных
Keyword: machine learning, question answering system, syntax tree, word2vec, nltk, pymorphy2, python, neural network analysis
Annotation: This article is devoted to design of automatic question-answering system based on free technologies of semantic text compression. A detailed analysis of modern solutions of knowledge extraction from big text data sets is performed. Lack of existing ready to using program products is shown. The ways to design of automatic frequently answering questions system are investigated. Existence of solutions for limited questions sets is discussed. A detailed analysis of scientific works in this field is performed. The main models of semiautomatic and fully automatic semantic questions analysis are described. The disadvantages of all popular methods are shown. Two ways to semantic representation of text phrases are revealed. The Continuous Bag of Words (CBOW) and Skip-gram algorithms are discussed. The detailed description of designed question answering software is shown. Examples of automatically matched existing phrases and semantically difficult real questions are given. The advantages of developed product are emphasized. The possibilities of using these technologies for solving similar tasks are discussed. In conclusion, the economic benefits of using free soft are emphasized.

Введение
Анализ информации – это одна из наиболее востребованных задач, возникающих сегодня во всех областях деятельности человека. Современные объёмы данных и требуемая скорость их обработки побуждают людей всё чаще использовать средства автоматизации анализа, базирующиеся на компьютерных технологиях. Некоторые аспекты данной области на сегодняшний день изучены хорошо и обеспечены соответствующим программным обеспечением. Это, например, статистический анализ числовой информации, распознавание печатного текста и т.д. К сожалению, до сих пор остаётся ряд широко востребованных в повседневной жизни задач анализа данных, не имеющих качественного и общедоступного автоматизирующего программного обеспечения. Среди них наиболее актуальна в настоящее время задача семантического сжатия больших объемов текстовой информации по определённой тематике [1], одним из наиболее значимых подмножеств которой является задача поиска в тексте ответа на заданный вопрос (задача полнотекстового поиска).
Одним из решений задачи полнотекстового поиска можно считать современные поисковые системы. Например, исследованию особенностей семантического поиска с использованием технологий Google посвящены работы В. Мала (V. Mala) [2], В.Н. Пху (V.N. Phu) [3]. Построение вопросно-ответной системы (question-answering system – QA system) для Википедии рассмотрено в работе Ф. Аббас (F. Abbas) [4].
К сожалению, результаты полнотекстового поиска, полученные с помощью механизмов современных поисковых систем, неудовлетворительны для тематических задач поиска. Причинами этого являются использование пользователями речевых конструкций естественного языка (например, вопросительных слов), высокая частота встречаемости искомых ключевых слов в просматриваемом тексте и другие проблемы, связанные с отсутствием семантического анализа вопроса и массива просматриваемых данных.
В общем случае говорить об автоматизированном поиске ответов на вопросы нельзя, так как всесторонний семантический анализ с использованием только компьютерных средств является AI-полной задачей [5], предполагающей разработку искусственного интеллекта, сопоставимого по возможностям с человеческим. Тем не менее, данная задача может иметь решение в рамках определённых ограничений.
Альтернативой полноценного семантического поиска ответов на вопросы является подход, базирующийся на конечных массивах данных и наличии достаточной для выявления закономерностей подборке запросов к ним. Простейшим примером данного подхода является решение задачи семантического поиска в виде набора часто задаваемых вопросов (frequently asked questions – FAQ) по исследуемой тематике. В данном случае есть два возможных направления автоматизации: решения с частичной автоматизацией без исключения человеческого фактора и решения с полноценной компьютерной автоматизацией.
Частично автоматизированные подходы
Идея подхода с использованием часто задаваемых вопросов очень проста. При таком подходе пользователю, прежде чем осуществлять просмотр всего массива данных по искомой тематике, предлагается обратиться к краткой выдержке из информации, к которой часто обращались другие посетители. Данная технология требует от пользователя времени на прочтение перечня вопросов и выявление среди них аналогичного своему, не гарантируя нахождения такового.
Решением задачи с частичной автоматизацией может быть подход на основе иерархических инструкций, просматриваемых специалистом. Причем реализация данных инструкций может быть, как компьютеризованной, так и «бумажной». Такой подход, например, используется в системах телефонной поддержки клиентов банков или операторов сотовой связи. Пользователю предлагается выбрать тему своего вопроса из списка предложенных тем. Дальнейший поиск ответа осуществляется путём соединения с оператором поддержки, имеющим инструкцию для решения часто возникающих ситуаций, заданную в виде древовидной структуры. Оператор, задавая пользователю вопросы и анализируя его ответы, продвигается по дереву сверху вниз и сообщает абоненту сведения, полученные в конечном листе инструкции. Такая система эффективно отвечает на вопросы пользователей, но её организация и поддержка предполагают большие финансовые затраты на персонал.
Автоматизированные подходы
Автоматизированный подходы к задаче построения вопросно-ответной систему обычно также оперируют некоторыми ограниченными массивами данных и подборкой заранее известных вопросов и ответов, позволяющей осуществить обучение системы. Например, в работе Д. Бхардважа (D. Bhardwaj) [6] рассматривается модель построения автоматизированной вопросно-ответной системы в формате FAQ, основанной на основе простейшего OR/AND-поиска и методов комбинаторики. Х. Баотьян (H. Baotian) в своей работе [7] используют для построения вопросно-ответной системы технологию нейронных сетей.
Особую сложность вопросу построения вопросно-ответной системы могут добавлять национальные особенности языка. В частности, на сегодняшний день есть большой ряд узкоспециализированных работ, посвящённых разработке вопросно-ответных систем для конкретных языковых групп. Например, в работе Силана А. (Saelan, A) [8] рассматривается построение подобной системы для индонезийского языка. В работе Мегьюхота Х. (Meguehout, H) [9] показано построение вопросно-ответной системы для арабского языка. Работы Медведя М. (Medved’, M.) [10] и Фама С.Т. (Pham, S.T.) [11] посвящены исследованиям в данной области для чешского и вьетнамского языков, соответственно.
Тем не менее, у большинства данных работ есть существенные недостатки. В основном это узко специализированные частные разработки, применение которых для задач других областей или других языковых групп невозможно. С другой стороны, существующие на сегодняшний день промышленные разработки являются преимущественно закрытыми программными продуктами, недоступными для широкого использования. В какой-то мере, к готовым технологиям, использующимися для семантического сжатия текста, можно отнести проект IBM Watson [12]. Данная разработка является дорогостоящим уникальным суперкомпьютерным проектом, использование которого в построение вопросно-ответных систем современного интернет сообщества не представляется экономически обоснованным.
Таким образом, задача разработки полноценной вопросно-ответной системы является актуальной и востребованной на сегодняшний день. Исходя из востребованности данной тематики, в НИЯУ МИФИ была разработана вопросно-ответная система, комбинирующая в себе свободные технологии семантической обработки текста, предоставляемые современными всемирно известными разработчиками, с актуальными алгоритмическими подходами обработки больших объёмов текстовой информации.
Разработка вопросно-ответной системы на основе расширенной модели часто задаваемых вопросов
В основе разработанной системы лежит практика часто задаваемых вопросов в расширенном виде. В структуру системы входит база вопросов по заданной тематике, которые могут задать пользователи. Каждому из них ставится в соответствие ответ, причем одному ответу могут соответствовать несколько вопросов. Таким образом, описанный подход сводит задачу нахождения ответа к поиску вопроса из базы, семантически близкого к заданному. Для того, чтобы решить эту задачу, формируются модели заданного вопроса и каждого вопроса из базы. В качестве моделей используются синтаксические деревья и геометрические вектора. В рамках рассматриваемой задачи сравнение подобных моделей является объективным показателем семантической близости вопросов.
Синтаксическое дерево — это построенный по определенному алгоритму граф, узлами которого являются отдельные части предложения. Ребрам, соединяющим узлы, соответствует их синтаксическая связь. В узле дерева могут располагаться таксономические единицы, отдельные слова предложения, или функциональные единицы, сочетания слов, которые при расщеплении перестают выполнять синтаксическую функцию. Существуют четыре основных алгоритма расположения узлов в графе: теория членов предложения, грамматика Теньера, грамматика зависимостей, грамматика непосредственно составляющих [13]. Теория членов предложения — это алгоритм, в котором в качестве вершины дерева выступает член предложения, не являющийся подчиненным по отношению ни к одной другой синтаксической единице. В соответствии с грамматикой Теньера вершиной синтаксического дерева является глагол-сказуемое. Кроме того, вводятся понятия актанты — функциональной единицы, обязательной по отношению к сказуемому и сирконстанты — необязательной (факультативной) функциональной единицы. Грамматика зависимостей — это алгоритм, при котором в узлах дерева располагаются таксономические единицы. Вершиной дерева является глагол-сказуемое или его аналитическая часть. В случае составного глагола, все связи в дереве подчинительные. Грамматика непосредственно составляющих — это алгоритм, в ходе выполнения которого каждая грамматическая единица делится на две более простых единицы. Подобное деление происходит вплоть до выделения в качестве узла отдельного слова, каждому узлу соответствует грамматический класс, среди которых все части речи, а также именная и глагольная составляющие.
Представление слова в векторном виде — сопоставление слова из словаря геометрическому вектору в пространстве Rn, где под словарём понимается пространство конечной размерности N, равной количеству всех представляемых в векторном виде слов. Задачей определения семантической близости между словами занимается дистрибутивная семантика. Увеличение размерности словесного векторного пространства способствует повышению точности определения смысловой близости, однако существует некоторая критическая размерность, превышая которую, модель не приносит заметного увеличения точности. Обычно размерность вектора устанавливается в диапазоне от 100 до 1000. Любой алгоритм построения векторного пространства стремится к максимизации косинусного сходства между векторами семантически близких слов. Косинусное сходство определяется формулой:
 ,
,
где A и B — вектора, расстояние между которыми вычисляется, θ — угол между ними. Одним из наиболее эффективных семантических анализаторов на сегодняшний день является word2vec — программное средство для построения словесных векторных пространств, разработанное компанией Google в 2013 году [14].
Word2vec основан на двухслойной нейронной сети прямого распространения, поэтому у пользователей существует возможность обучить сеть на собственных текстовых корпусах и, таким образом, получить наиболее подходящую для решения текущей задачи векторную модель. Результаты обучения модели зависят от выбранной пользователем модельной архитектуры. Всего в word2vec реализованы два алгоритма обучения: Continuous Bag of Words (CBOW) и Skip-gram.
При использовании архитектуры CBOW алгоритм предсказывает слово, исходя из его контекста, т.е. анализируя наборы слов, находящиеся по правую и левую стороны от данного. При этом результат работы алгоритма не зависит от порядка контекстных слов. Входным элементом в нейронную сеть выступает набор контекстных векторов w(t-k),.., w(t-1), w(t+1), ..., w(t+k) , а выходным вектором — w(t), где w(t) — вектор предсказанного на основе контекста слова. Архитектура Skip-gram отличается от CBOW тем, что предсказывает набор слов вокруг, основываясь на данном слове. Входным вектором выступает w(t), а выходным элементом — множество M = {w(t-k),.., w(t-1), w(t+1), ..., w(t+k)}, где M — множество векторов. Каждое слово, соответствующее векторам из множества М, характеризует слово, соответствующее входному вектору. Схема работы алгоритмов CBOW и Skip-gram показана на рисунке 1.
Работу word2vec можно разделить на пять этапов. На первом этапе происходит статистическая обработка входного текстового корпуса, то есть для каждого слова рассчитывается количество вхождений его в исходный корпус.
На втором этапе происходит сортировка слов по частоте вхождения, а также, в целях оптимизации работы с памятью, удаляются так называемые гапаксы — слова, встречающиеся редко в сравнении с другими словами текста. Результаты работы данного этапа сохраняются в хеш-таблице.

Рис. 1. Схема работы алгоритмов CBOW и Skip-gram
На третьем этапе для сжатия данных к полученной хеш-таблице применяется код Хаффмана — алгоритм оптимального префиксного кодирования. В результате применения данного алгоритма чаще встречающиеся слова кодируются меньшим количеством бит, а реже встречающиеся — большим.
Четвертый этап заключается в суб-сэмплировании самодостаточной выборки из текстового корпуса (например, предложения или абзаца). В ходе данного процесса из выборки удаляются наиболее часто встречающиеся слова, так как они обычно не несут значимого смысла. Операция суб-сэмплирования применяется для уменьшения времени обучения модели.
Hа пятом этапе к получившейся выборке применяется один из алгоритмов обучения, рассмотренных выше: CBOW или Skip-gram.
Разработанная в НИЯУ МИФИ вопросно-ответная система включает в себя следующие элементы: управляющие скрипты; обученная на Национальном корпусе русского языка векторная Skip-gram-модель в 300-мерном пространстве [15, 16], содержащая более 184000 лемм; база ответов на вопросы, сами вопросы, а также их векторное представление.
Так как технология Word2vec применима как к отдельным словам, так и к текстам, в данном случае являющимся вопросительными предложениями, то с её помощью на основе любой текстовой выборки можно построить соответствующее векторное представление путём суммирования векторов слов, входящих в выборку. Каждое слово из предложения должно быть лемматизировано, так как в векторную модель входят только леммы, то есть слова в словарной форме, а сама форма не имеет значения в определении смысла слова. Некоторые части речи, такие как существительные, глаголы и прилагательные, в большинстве случаев являются семантически значимыми, тогда как другие части речи, например, предлоги, союзы и местоимения не несут смысловой нагрузки. Поэтому при анализе предложения к ним применяется фильтрация, в ходе которой из него исключаются так называемые стоп-слова [17] и знаки препинания. Пример подготовки предложения к построению векторной модели изображен на рисунке 2.

Рис 2. Пример анализа предложения
Управляющие скрипты написаны на языке Python. Лемматизация производится средствами библиотеки pymorphy2 [18], которая в настоящий момент способна обрабатывать до 100000 слов в секунду, при этом потребление оперативной памяти колеблется от 10 до 20 Мб [19]. Набор используемых стоп-слов взят из библиотеки Natural Language Toolkit [20], которая используется в проектах, связанных с компьютерной лингвистикой и машинным обучением, и предназначена для обработки естественного языка.
Процесс реализации вопросно-ответной системы был разделён на несколько этапов. Так как система базируется на практике часто задаваемых вопросов, то на первом этапе было осуществлено проектирование базы вопросов и ответов.
На втором этапе в базу были внесены векторные представления каждого вопроса, построенные по одному из ранее описанных алгоритмов. Затем этот же алгоритм применяется к вопросу, заданному пользователем системы. Таким образом, система получает необходимую для определения семантической близости информацию, на основе которой может делать предположения о смысловом сходстве или различии заданного вопроса и вопросов из базы.
На заключительном этапе для каждого вопроса из базы и заданного пользователем вопроса были вычислены значения косинусного сходства. Результатом работы системы является ответ на тот вопрос из базы, косинусное сходство с которым максимально. Схема принципа работы системы изображена на рисунке 3.
Разработанная система оформлена в виде удалённого робота (бота), отвечающего на вопросы посредством HTTP-протокола. Для тестирования разработанной системы использовалась технология Microsoft Bot Framework Channel Emulator [21]. Пример тестирования вопросно-ответной системы показан на рисунке 4.

Рис 3. Схема принципа работы системы
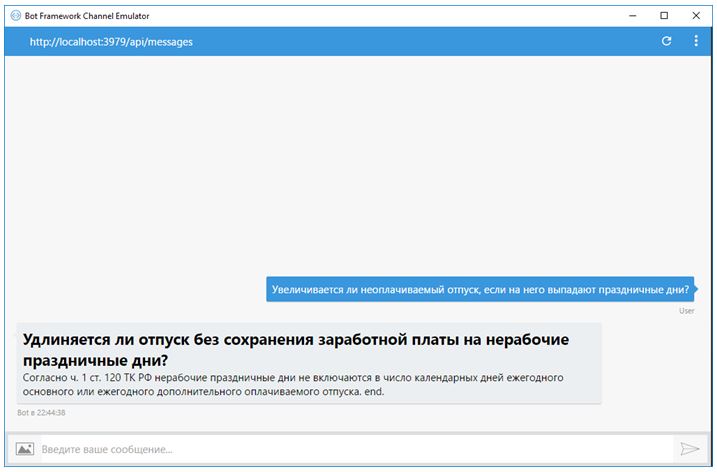
Рис 4. Пример работы системы
Тестирование системы выявило высокое качество поиска ответов, даже для вопросов семантически сложных с точки зрения сопоставления с вопросами, для которых готовы ответы. Примеры заданных вопросов и поставленных им в соответствие вопросов из базы FAQ показаны в таблице 1.
Таблица 1
Примеры заданных вопросов и поставленных им в соответствие вопросов из базы FAQ
|
Вопрос пользователя |
Вопрос в базе |
|
Должен ли сотрудник находиться на рабочем месте, если сейчас работы нет? |
Обязан ли работник находиться во время простоя на рабочем месте? |
|
Может ли сотрудник сменить банк, который выплачивает заработную плату? |
Имею ли я право поменять банк для выплаты заработной платы? |
|
Включены ли в оклад надбавки за учёную степень? |
Надбавки за ученую степень должны выплачиваться в виде премий или они уже включены в оклад? |
|
Может ли руководитель не проходить обучение по охране труда? |
Обязательно ли руководителю организации проходить обучение по охране труда? |
|
Является ли договор без паспортных данных работника легитимным? |
Если в договоре отсутствуют паспортные данные работника, будет ли договор считаться заключенным? |
|
Ограничен ли период действия ученического договора? |
Установлен ли максимальный срок действия ученического договора? |
|
Можно ли уволить сотрудника, если тот подал поддельный паспорт? |
Может ли работник быть уволен за предоставление поддельных документов при приеме на работу? |
|
Как индексируется зарплата сотрудника? |
Необходимо ли индексировать заработную плату работника? |
|
Предоставляется ли выходной в другой день, если в праздник был рабочий день? |
Может ли быть предоставлен другой день отдыха работнику, работавшему в выходной или нерабочий праздничный день? |
|
Должен ли работодатель давать сотрудникам отдыхать? |
Обязан ли работодатель предоставлять работникам отпуска? |
Заключение
Разработанная в НИЯУ МИФИ система семантического анализа является полноценным продуктом и представляет собой простое и эффективное решение задачи построения вопросно-ответных систем. Она способна найти применение во многих социальных, научных и бизнес задачах. Представленный подход к её реализации, основанный на технологиях word2vec, nltk и pymorphy2, имеет значительные преимущества в сравнении с большинством использующихся на настоящий момент разработок. Word2vec и nltk распространяются под свободной лицензией Apache 2.0. Pymorphy2 распространяется под свободной лицензией MIT. Таким образом, данные технологии могут быть беспрепятственно использованы при разработке коммерческих продуктов, что, в свою очередь, обуславливает высокую экономическую эффективность созданного подхода. В итоге, можно отметить, что построение вопросно-ответных систем на основе нейросетей является перспективным направлением в практическом применении механизмов машинного обучения.
1. Ceglarek, D.: Semantic Compression for Text Document Processing.// Proceedings of Transactions on Computational Collective Intelligence XIV, Springer, Heidelberg, 2014. – С20–48.
2. Mala V., Lobiyal D.K. Semantic and keyword based web techniques in information retrieval // Proceedings of Computing, Communication and Automation (ICCCA), International Conference, 2016 – С23–26.
3. Phu, V.N., Chau, V.T.N., Dat, N.D., Tran, V.T.N., Nguyen, T.A. A valences-totaling model for English sentiment classification // Knowledge and Information Systems, 2017 – С1–58.
4. Abbas, F., Malik, M.K., Rashid, M.U., Zafar, R. WikiQA - A question answering system on Wikipedia using freebase, DBpedia and Infobox // Proceedings of Sixth International Conference on Innovative Computing Technology (INTECH), 2016 – С185–193.
5. Raymond E.S., The New Hacker's Dictionary — MIT Press, 1996. —547 с.
6. Bhardwaj, D., Pakray, P., Bentham, J., Saha, S., Gelbukh, A. Question answering system for frequently asked questions // CEUR Workshop Proceedings, Vol. 1749, 2016 – С1–5.
7. Hu, B., Lu, Z., Li, H., Chen, Q. Convolutional neural network architectures for matching natural language sentences // Advances in Neural Information Processing Systems, № 3, 2014 – С2042-2050.
8. Saelan, A., Purwarianti, A., Widyantoro, D.H. Question analysis for Indonesian comparative question // Journal of Physics: Conference Series, Vol. 801, Iss. 1, 2017 – С1–6.
9. Meguehout, H., Bouhadada, T., Laskri, M.T. Semantic role labeling for Arabic language using case-based reasoning approach // International Journal of Speech Technology № 2, 2017, – С1-10
10. Medved’, M., Horák, A. AQA: Automatic question answering system for Czech // Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Vol. 9924, 2016, – С270-278.
11. Pham, S.T., Nguyen, D.T. A Computational and Inferential Method for Analyzing the Semantics of Phrase and Sentence in Vietnamese Question Answering System Model (VietQASM) // Proceedings of Asia Modelling Symposium 2015 – Asia 9th International Conference on Mathematical Modelling and Computer Simulation, 2016, – С107-112.
12. Fan, J., Kalyanpur, A., Gondek, D.C., Ferrucci, D.A., Automatic knowledge extraction from documents // IBM Journal of Research and Development, Vol. 56, Iss. 3-4, 2012 – С5:1–5:10.
13. Касевич В.Б. Структура предложения. Элементы общей лингвистики. — М.: Наука, 1977. —183 с.
14. Mikolov T., Sutskever I., Chen K., Corrado G., Dean J. Distributed Representations of Words and Phrases and their Compositionality // Proceedings of the 26th International Conference on Neural Information Processing Systems, USA, 2013 – С3111–3119.
15. Kutuzov A., Andreev I. Texts in, Meaning Out: Neural Language Models in Semantic Similarity Task for Russian // Proceedings of the Dialog 2015 Conference. Moscow, Russia, 2015 – С143–154.
16. http://ling.go.mail.ru – официальный сайт проекта RusVectōrēs (дата последнего обращения 22.05.2017).
17. Manning C.D., Raghavan P., Schütze H. An Introduction to Information Retrieval, Cambridge University Press, Cambridge, England, 2009. —547 с.
18. Korobov M.: Morphological Analyzer and Generator for Russian and
Ukrainian Languages // Proceedings of International Conference on Analysis of Images, Social Networks and Texts, 2015. – С320–332.
19. http://pymorphy2.readthedocs.io – официальный сайт проекта pymorphy2 (дата последнего обращения 22.05.2017).
20. http://www.nltk.org/ – официальный сайт проекта Natural Language Toolkit (дата последнего обращения 22.05.2017).
21. https://docs.microsoft.com/en-us/bot-framework/cognitive-services-bot-intelligence-overview – обзор технологии Microsoft Bot Framework Channel Emulator (дата последнего обращения 22.05.2017).
1. Ceglarek, D.: Semantic Compression for Text Document Processing in Proceedings of Transactions on Computational Collective Intelligence XIV, Springer, Heidelberg, 2014. – pp. 20–48.
2. Mala V., Lobiyal D.K. Semantic and keyword based web techniques in information retrieval in Proceedings of Computing, Communication and Automation (ICCCA), International Conference, 2016 – pp. 23–26.
3. Phu, V.N., Chau, V.T.N., Dat, N.D., Tran, V.T.N., Nguyen, T.A. A valences-totaling model for English sentiment classification in Knowledge and Information Systems, 2017 – pp. 1–58.
4. Abbas, F., Malik, M.K., Rashid, M.U., Zafar, R. WikiQA - A question answering system on Wikipedia using freebase, DBpedia and Infobox in Proceedings of Sixth International Conference on Innovative Computing Technology (INTECH), 2016 – pp. 185–193.
5. Raymond E.S., The New Hacker's Dictionary — MIT Press, 1996. —547 p.
6. Bhardwaj, D., Pakray, P., Bentham, J., Saha, S., Gelbukh, A. Question answering system for frequently asked questions in CEUR Workshop Proceedings, Vol. 1749, 2016 – pp. 1–5.
7. Hu, B., Lu, Z., Li, H., Chen, Q. Convolutional neural network architectures for matching natural language sentences in Advances in Neural Information Processing Systems, # 3, 2014 – pp. 2042-2050.
8. Saelan, A., Purwarianti, A., Widyantoro, D.H. Question analysis for Indonesian comparative question in Journal of Physics: Conference Series, Vol. 801, Iss. 1, 2017 – pp. 1–6.
9. Meguehout, H., Bouhadada, T., Laskri, M.T. Semantic role labeling for Arabic language using case-based reasoning approach in International Journal of Speech Technology # 2, 2017, – pp. 1-10
10. Medved’, M., Horák, A. AQA: Automatic question answering system for Czech in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Vol. 9924, 2016, – pp. 270-278.
11. Pham, S.T., Nguyen, D.T. A Computational and Inferential Method for Analyzing the Semantics of Phrase and Sentence in Vietnamese Question Answering System Model (VietQASM) in Proceedings of Asia Modelling Symposium 2015 – Asia 9th International Conference on Mathematical Modelling and Computer Simulation, 2016, – pp. 107-112.
12. Fan, J., Kalyanpur, A., Gondek, D.C., Ferrucci, D.A., Automatic knowledge extraction from documents in IBM Journal of Research and Development, Vol. 56, Iss. 3-4, 2012 – pp. 5:1–5:10.
13. Kasevich V.B. Structure of Sentence. The Elements of Common Linguistic. — Moscow, Science, 1977. —183 p.
14. Mikolov T., Sutskever I., Chen K., Corrado G., Dean J. Distributed Representations of Words and Phrases and their Compositionality in Proceedings of the 26th International Conference on Neural Information Processing Systems, USA, 2013 – pp. 3111–3119.
15. Kutuzov A., Andreev I. Texts in, Meaning Out: Neural Language Models in Semantic Similarity Task for Russian in Proceedings of the Dialog 2015 Conference. Moscow, Russia, 2015 – pp. 143–154.
16. http://ling.go.mail.ru – official site of RusVectōrēs project (last access date 22.05.2017).
17. Manning C.D., Raghavan P., Schütze H. An Introduction to Information Retrieval, Cambridge University Press, Cambridge, England, 2009. —547 p.
18. Korobov M.: Morphological Analyzer and Generator for Russian and
Ukrainian Languages in Proceedings of International Conference on Analysis of Images, Social Networks and Texts, 2015. – pp. 320–332.
19. http://pymorphy2.readthedocs.io – official site of pymorphy2 project (last access date 22.05.2017).
20. http://www.nltk.org/ – official site of Natural Language Toolkit project (last access date 22.05.2017).
21. https://docs.microsoft.com/en-us/bot-framework/cognitive-services-bot-intelligence-overview – review of Microsoft Bot Framework Channel Emulator technology (last access date 22.05.2017).
архив: 2013 2012 2011 1999-2011 новости ИТ гость портала 2013 тема недели 2013 поздравления
E-mail редакции: vzh85@yandex.ru, 