| INNOV.RU | Информационный портал |
Разработка системы прогнозирования риска развития ишемической болезни сердца на основе нейронной сети с использованием корреляционного анализа признаков
Development of system for predicting the risk of coronary heart disease based on neural network using correlation analysis of features
УДК 004.891.3
Выходные сведения: Мусаев Н.Я., Белова И.М. Разработка системы прогнозирования риска развития ишемической болезни сердца на основе нейронной сети с использованием корреляционного анализа признаков // Иннов: электронный научный журнал, 2018. №7 (40). URL: http://www.innov.ru/science/tech/razrabotka-sistemy-prognozirovaniya/
Авторы:
Мусаев Н.Я.1, Белова И.М.2
1 студент 4-го курса бакалавриата по направлению «Информатика и вычислительная техника», федеральное государственное бюджетное образовательное учреждение высшего образования «Московский политехнический университет», Москва, Российская Федерация (107023, г. Москва, ул. Б. Семёновская, 38), e-mail: nurlancik1@gmail.com
2 к.ф.-м.н., доцент кафедры ВМ-2, МТУ МИРЭА, Москва, Российская Федерация (119454, г. Москва, проспект Вернадского, 78), e-mail: irbelova1@gmail.com
Authors:
Musayev N.Ya.1, Belova I.M.2
1 fourth year BA-student, specialty “Informatics and computer systems”, Moscow Polytechnic University, Moscow, Russian Federation (107023, Moscow, Bolshaya Semenovskaya st., 38), e-mail: nurlancik1@gmail.com
2 Ph.D., assistant professor of dept. Higher Mathematics 2, MTU MIREA, Moscow, Russian Federation (119454, Moscow, Vernadsky avenue, 78), e-mail: irbelova1@gmail.com
Ключевые слова: система прогнозирования, ишемическая болезнь сердца, машинное обучение, нейросетевой анализ данных, оптимизация нейронных сетей, медицина, Python, Keras
Keyword: prediction system, coronary heart disease, machine learning, neural network analysis, optimization of neural networks, medicine, Python, Keras
Данная статья посвящена исследованию вопроса оптимизации работы нейронных сетей с помощью корреляционного анализа признаков для прогнозирования риска развития ишемической болезни сердца. В результате анализа литературных источников были выявлены недостатки ранее разработанных программных средств, серьезно ограничивающие применение этих программ в медицинской сфере.
В настоящей работе используются специальные отображающие слои в нейронной сети, которые работают по принципу таблиц поиска. Показывается преимущество их применения для приведения категориальных признаков к представлению, с которым эффективно способна работать нейронная сеть. На основе сравнительного анализа выбраны функции активации для каждого слоя, функция стоимости и алгоритм оптимизации нейронной сети. Подробно описаны метод для отбора признаков на основе работы построенной модели и основанный на поведении модели метод корреляционного анализа, который позволит решить характерную для нейронных сетей проблему «черного ящика». На основе оптимизированной нейронной сети была разработана автоматизированная система прогнозирования риска развития ишемической болезни сердца. При разработке системы использовалось только свободно распространяемое программное обеспечение. Выполнен сравнительный анализ предложенного метода с методом опорных векторов, наивным байесовским классификатором и полносвязной нейронной сетью. Внедрение разработанной системы позволит медицинским учреждениям повысить оперативность и точность предварительной диагностики пациентов.
Annotation: Coronary heart disease is one of the leading causes of death in the world. To improve the effectiveness of early diagnosis of the disease, many studies have been conducted on clinical decision support systems using technologies such as Data mining and machine learning. One of the widely used methods of machine learning are neural networks.
This article deals with study of neural network optimization using correlation analysis to predict the risk of coronary heart disease. The analysis of the literature revealed the disadvantages of previously developed software, which seriously limit its application in the medical field.
In this paper we use embedding layers in the neural network, functioning on the principle of lookup tables. The advantage of their application is shown to bring categorical features to a representation with which the neural network is effectively capable of operating. Based on the comparative analysis, the activation functions for each layer, the cost function and the neural network optimization algorithm are selected. The method for selecting features based on the work of the constructed model is described in detail and the correlation analysis method based on the behavior of the model that will solve the problem of the "black box" characteristic for neural networks is described. The automated system for predicting the risk of coronary heart disease has been developed on the base of optimized neural network. Only free software was used in the development of the system. A comparative analysis of the proposed method with SVM, naive Bayes classifier, and a fully connected neural network is performed. The use of the developed system will allow medical institutions to increase the efficiency and accuracy of preliminary diagnosis of patients.

Введение
Ишемическая болезнь сердца является главной причиной смертности во всем мире. Так, по данным Всемирной организации здравоохранения, от ишемического инсульта в 2016 году умерло 9,43 миллионов человек [1].
Чаще всего медицинские специалисты ставят диагнозы на основе результатов электрокардиографии, ангиографии и анализа крови. На раннем этапе болезнь диагностируется с трудом [2,3], однако для эффективного лечения очень важна ранняя диагностика. Диагнозы ставятся на основе личного опыта и квалификации медицинских работников, что приводит к увеличению рисков допущения ошибок, задержки необходимого лечения, следовательно, и времени лечения, таким образом, наблюдается существенное увеличение затрат на лечение пациента. Чтобы избавиться от этих недостатков, было проведено множество исследований в области клинических систем поддержки принятия решений с использованием таких технологий, как Data mining и машинное обучение.
Из методов машинного обучения, которые были использованы для прогнозирования риска развития данной болезни, для повышения точности работы широко используются нейронные сети [4,5]. Было проведено большое количество исследований в области прогнозирования риска развития ишемической болезни сердца с использованием машинного обучения. Например, в работе Арабасади [6], опубликованной в 2017 году, была предложена гибридная нейросетевая модель с использованием генетического алгоритма для решения задачи прогнозирования риска развития ишемической болезни сердца. Входные данные были отобраны с помощью генетического алгоритма и предиктор риска развития болезни был смоделирован с помощью нейронной сети. А Нараин [7] в своей работе описал разработку системы прогнозирования риска ИБС, смоделированной с помощью квантовой нейронной сети. Главным отличием данной работы являлось то, что при обучении нейросетевой модели производилось увеличение квантового интервала в соответствии со значением функции стоимости. Кьюкар [8] предложил системы прогнозирования риска развития ишемической болезни сердца с использованием байесовских нейронных сетей на основе данных ЭКГ.
Несмотря на то, что разработанные программные средства на основе нейронных сетей дали значимые результаты для клинических экспериментов, медицинские специалисты недовольны характерными для данной технологии свойствами «черного ящика» [9], вследствие чего прогностические модели обучаются без знания взаимосвязи между входными признаками и выходами нейронной сети. Так как для прогнозирования в медицинской сфере прогностическая модель должна объяснять логику своей работы, данная проблема является серьезным ограничением.
Таким образом, работа посвящена разработке системы прогнозирования риска развития ишемической болезни сердца на основе нейронной сети с использованием корреляционного анализа признаков, лишенной проблемы «черного ящика».
Материалы и методы
Искусственная нейронная сеть - это статистическая модель, имитирующая принцип работы биологических нейронных сетей. Обучение нейронной сети заключается в модификации синаптических весов. Сходства искусственной нейронной сети с мозгом заключаются в двух аспектах:
· Информация поступает в нейронную сеть извне и используется в процессе её обучения;
· Для накопления знаний применяются синаптические веса, которые могут быть настроены с помощью алгоритма обучения.
В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными и выходными данными, а также выполнять обобщение [10]. Следовательно, после удачного обучения сеть будет способна выдавать корректные результаты для новых данных, которые могут быть даже частично искажены.
Систему прогнозирования риска развития ишемической болезни сердца было решено построить на основе многослойной нейронной сети прямого распространения, поскольку данная архитектура относительная проста и широко применяется для прогнозирования. В качестве входных данных будут выступать признаки категориального или количественного типа, которые характеризуют историю болезни пациента. Модель будет устроена так, чтобы категориальные данные передавались в сеть отдельно от остальных и обрабатывались специальным скрытым слоем, поскольку для работы с такими данными необходимо привести их к удобному для работы представлению.
Главное правило анализа категориальных данных в нейронных сетях заключается в том, чтобы каждая категория характеризовалась своим входным сигналом. Чтобы это выполнить, можно использовать векторные представления, что позволит сопоставить вектор из действительных чисел к каждой категории. Самым распространенным и широко используемым методом преобразования категории в вектор является прямое кодирование. При использовании прямого кодирования мы получаем разреженную матрицу, где каждый новый столбец представляет одно возможное значение какого-либо одного признака.
Главным недостатком данного метода являются слишком большие затраты физической памяти, из которого следует более длительное обучение нейронной сети или даже ухудшение итоговых результатов. Другой недостаток прямого кодирования – потеря информации в тех случаях, когда имеет значение порядок категорий.
В настоящей работе использовались специальные отображающие слои, которые работают по принципу таблиц поиска. Для каждого категориального признака создается тензор заданного размера, который заполняется векторами из случайных чисел. После обучения отображающего слоя тензор будет хранить вектора, наиболее близко характеризующие категориальные данные для решаемой задачи. Таким образом, при работе модели и обработке категориальных данных физическая память будет затрачиваться в установленных самим пользователем пределах, а векторное представление данных будет оптимальным для решаемой задачи.
В качестве функции активации нейронов скрытого слоя лучшие результаты дало применение функции «выпрямитель», которая имеет следующую формулу f(x)=max(0,x) и реализует простой пороговый переход в нуле. Нейроны с данной функцией активации называются ReLU. Главные преимущества данных нейронов:
· В отличие от сигмоидальной и тангенциальной функций активации, которые требуют выполнения ресурсоёмких операций, ReLU реализуется с помощью порогового преобразования матрицы активаций в нуле.
· Повышение скорости сходимости стохастического градиентного спуска по сравнению с сигмоидой и гиперболическим тангенсом, обусловленное линейным характером и отсутствием насыщения данной функции.
Для данных, на которых будет обучаться создаваемая модель, количество классов результирующего признака равняется двум: «болен» и «не болен». Однако возможен и анализ данных с большим количеством результирующих классов.
В случае бинарной классификации выходной слой нейронной сети будет состоять из одного нейрона с сигмоидальной функцией активации:
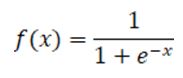
Эта функция позволяет получить выходное значение в диапазоне от 0 до 1. Также она является дифференцируемой, что позволяет применить для обучения сети метод обратного распространения ошибки.
В случае же многоклассовой классификации количество нейронов в выходном слое будет равняться количеству требуемых классов, а их функцией активации будет являться функция Softmax, или же нормированная экспоненциальная функция:

Эта функция является обобщением логистической функции, которое сжимает K-мерный вектор z из произвольных вещественных чисел в K-мерный вектор σ(z) из вещественных чисел в диапазоне от 0 до 1, сумма которых равна 1.
На каждом обучающем примере модель будет выдавать значение, моделирующее нужное вероятностное распределение, а для сравнения двух вероятностных распределений необходима корректная мера. В качестве такой меры будет использоваться бинарная кросс-энтропия. Замена квадратичной функции на функцию кросс-энтропии в функции стоимости зачастую позволяет бороться с насыщением нейронов и ускорять обучение нейронной сети [11]. Кросс-энтропия определяется формулой:
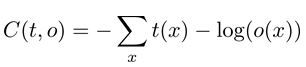
где: x – обучающий пример;
t – желаемый результат;
o – полученный результат.
Посмотрев на формулу, можно заметить, что вклад в функцию стоимости будет низким, если фактический выход близок к желаемому результату. При использовании этой функции наклон кривой стоимости будет намного круче, чем исходная плоская область на соответствующей кривой для квадратичной функции стоимости. Эта крутизна позволяет избежать замедления обучения, что характерно для квадратичной функции стоимости.
Если в качестве функции стоимости нейронной сети в случае многоклассовой классификации применяется категорийная кросс-энтропия, то при бинарной классификации используется бинарная кросс-энтропия, которая является специальной модификацией функции кросс-энтропии и выглядит следующим образом:
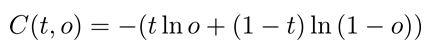
где: t – желаемый результат;
o – полученный результат.
Определившись с функцией стоимости, можно приступать к решению задачи минимизации её значения. Для решения будем использовать градиентный метод оптимизации, а именно метод Adam. Это алгоритм градиентной оптимизации стохастических целевых функций, который основан на адаптивных оценках моментов младшего порядка. Он вычисляет индивидуальные адаптивные скорости обучения для разных параметров из оценок первого и второго моментов градиентов. Данный метод прост в реализации, является эффективным с точки зрения вычислительной мощности, имеет небольшие требования к памяти, инвариантен к диагональному масштабированию градиентов и хорошо подходит для задач, которые являются большими с точки зрения данных или параметров. Он также подходит для нестационарных целей и проблем с очень шумными или разреженными градиентами. Гиперпараметры, необходимые для работы алгоритма, имеют интуитивные интерпретации и обычно требуют небольшой настройки. Эмпирические результаты показывают, что Adam хорошо работает на практике и выгодно отличаются от других методов стохастической оптимизации [12]. Данный метод рассматривают как комбинацию импульсивного метода с RMSProp с небольшими модификациями:
1) В Adam импульс непосредственно включен в виде оценки первого момента градиента.
2) Он включает поправку на смещение в оценки как первых моментов, так и вторых моментов для учета их инициализации в начале координат.
Adam считается довольно устойчивым к выбору гиперпараметров, хотя скорость обучения иногда нужно брать отличной от предлагаемой по умолчанию.
Построив модель вышеописанным образом, мы получим полносвязную нейронную сеть, которая будет способна после обучения на обучающем наборе данных предсказывать риск развития ишемической болезни сердца у пациента. Однако модели всё ещё присущи характеристики «черного ящика», вследствие чего она обучается без знания известных взаимоотношений между признаками. Для решения данной проблемы проводился трёхэтапный анализ признаков с соответствующими модификациями первоначальной модели:
1) Отбор значимых признаков с помощью статистических методов;
2) Отбор значимых признаков с помощью нейронной сети;
3) Корреляционный анализ признаков с помощью нейронной сети.
Загрузив в систему набор анализируемых данных, в первую очередь, нужно отсеять признаки, которые никак не влияют на результирующий признак. Данную задачу частично можно решить с помощью статистических методов: U-критерий Манна-Уитни и критерий хи-квадрат Пирсона.
U-критерий Манна-Уитни — это непараметрический критерий статистического вывода, применяемый для проверки различия между двумя группами при использовании порядковых данных [13]. Чем меньше значение критерия, тем вероятнее, что различия между значениями параметра в выборках достоверны.
В том случае, если значение критерия «хи-квадрат» больше критического, можно сделать вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
После отсеивания незначимых признаков, легко выявляемых с помощью статистического анализа, для дополнительной оптимизации необходимо её продолжить на основе обученной нейронной сети. Для этого введём понятие чувствительности признака Sen(X,xi), которая будет характеризовать вклад, вносимый признаком в результат работы модели. Чувствительность признака вычисляется как среднее значение изменения выхода сети при добавлении к заданному признаку исходных данных xi очень маленького шума δ:
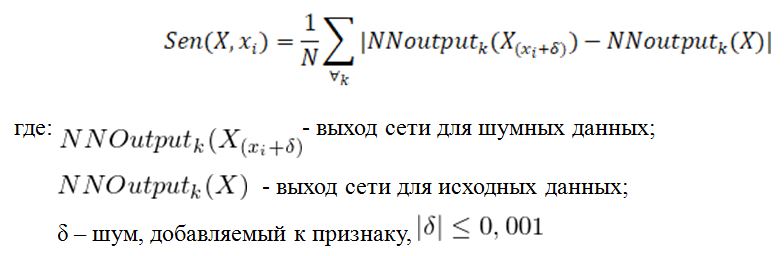
На вход обученной нейронной сети подаётся набор данных, в котором определённому признаку добавляется шум и вычисляется его чувствительность. После вычисления чувствительности всех признаков производится их сортировка в убывающем порядке. Признак с наименьшей чувствительностью является наименее значимым для модели, поэтому его можно исключить. Затем нейронную сеть необходимо переобучить на оставшихся признаках и проверить, не наблюдаются ли потери производительности по сравнению с предыдущей моделью. Если производительность не ухудшается, то процесс повторяется до тех пор, пока не будет определен минимальный список значимых признаков. Схема отбора значимых признаков с помощью нейронной сети приведена на рисунке 1.
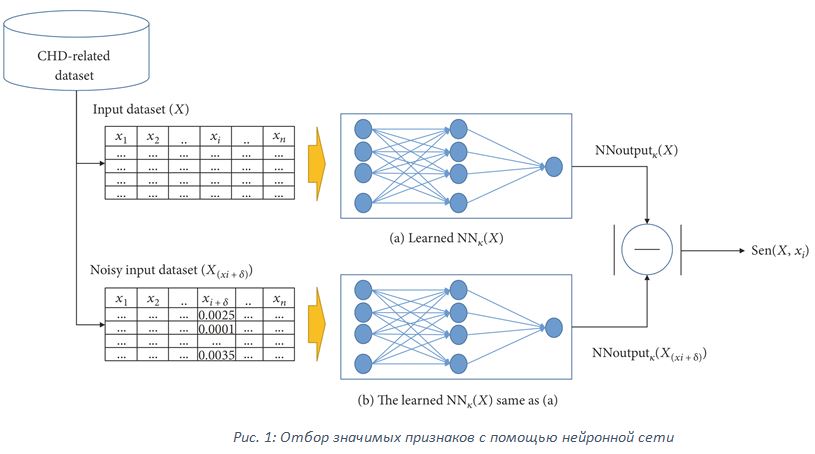
Корреляция — это статистическая зависимость между случайными величинами, не имеющая строго функционального характера, при которой изменение одной из случайных величин приводит к изменению среднего другой [14]. Показателем степени тесноты корреляционной связи является коэффициент корреляции r, который может находиться в диапазоне от -1 до 1, т.е. -1 ≤ r ≤ 1.
С целью устранения характеристик «черного ящика» будет применяться корреляционный анализ на основе нейронной сети, базирующийся на показателях чувствительности признаков. Коррелирующие признаки будут определяться в зависимости от взаимного влияния на изменения чувствительности [15]. Иными словами, если усиление значения одного из признаков значимо влияет на чувствительность других признаков, то соответствующие признаки можно рассматривать как коррелирующие. Определив тесноту связи между признаками, перестраиваем исходную модель таким образом, чтобы коррелирующие признаки были связаны с одним скрытым нейроном. Схема корреляционного анализа признаков на основе нейронной сети изображена на рисунке 2.
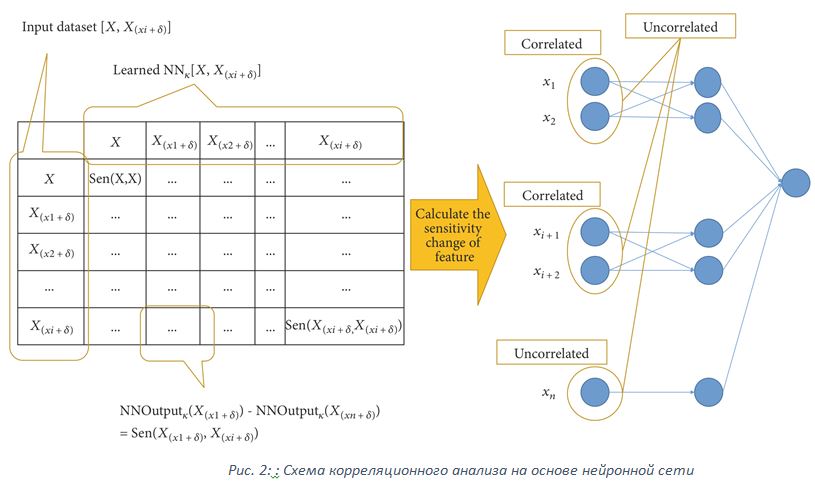
Результатом последнего этапа будет являться готовая для эксплуатации нейросетевая модель, обученная на медицинских данных и лишенная характеристик «чёрного ящика» благодаря структуре, учитывающей известные взаимосвязи признаков.
Выбор средств разработки был осуществлен исходя из требования высокой скорости и эффективности разработки. Для разработки системы прогнозирования был выбран следующий набор технологий:
· язык программирования Python;
· нейросетевая библиотека Keras [16];
· библиотека для обработки и анализа данных pandas [17].
Для выбранных средств характерны удобство использования в сочетании с хорошим быстродействием, широким функционалом и высокой производительностью.
Результаты и обсуждение
В качестве анализируемой выборки взята свободная база данных результатов различных обследований пациентов Кливлендской клиники [18]. Она включает в себя 303 записи и содержит 76 атрибутов, но рекомендуется работать лишь с 14 из них. В таблице 1 приведено описание признаков анализируемой выборки.
Таблица 1: Описание признаков анализируемых данных
|
Обозначение |
Название признака |
Тип признака |
|
age |
Возраст |
Непрерывный |
|
sex |
Пол |
Категориальный |
|
cp |
Тип боли в грудной клетке |
Категориальный |
|
trestbps |
Остаточное артериальное давление |
Непрерывный |
|
chol |
Холестерин |
Непрерывный |
|
fbs |
Уровень сахара в крови натощак |
Категориальный |
|
restecg |
Результат ЭКГ в состоянии покоя |
Категориальный |
|
thalach |
Максимальная ЧСС во время стресс-теста таллия |
Непрерывный |
|
exang |
Индуцированная стенокардия |
Категориальный |
|
oldpeak |
Депрессия сегмента ST, вызванная физическими упражнениями относительно покоя |
Непрерывный |
|
slope |
Наклон пика сегмента ST |
Категориальный |
|
ca |
Количество крупных сосудов при рентгеноскопии |
Дискретный |
|
thal |
Результат таллийного стресс-теста |
Категориальный |
|
num |
Болезнь сердца |
Категориальный |
В качестве обучающей выборки были взяты 70% записей, а оставшиеся 30% использовались как проверочная выборка для оценки производительности системы.
Результаты применения критериев Манна-Уитни и хи-квадрат с уровнем значимости, равным 0,05, показывают, что незначимыми для результата признаками являются fbs и restecg. Поэтому убираем все значения этих атрибутов из обучающей и проверочной выборок.
Таким образом, первоначальная модель нейронной сети будет состоять из 11 входных нейронов, 4 нейронов скрытого слоя и одного выходного нейрона.
Точность модели, обученной на нормализованной обучающей выборке, состоящей из 212 записей, в течение 10 эпох на проверочной выборке из 91 записи составила 91,11%.
В результате отбора признаков на нейронной сети, самыми значимыми признаками являются sex, thal и cp, а незначимым признаком является age. Сеть была переобучена с данными, не включающими данный признак, что привело к деградации производительности модели с 91,11% к 86,67%.
Корреляционные характеристики каждого признака были определены в соответствии с взаимным воздействием на изменения чувствительности. Выяснилось, что коррелирующие признаки влияют на изменение чувствительности друг друга за счет усиления одного признака. Коррелирующими между собой признаками являются chol, cp, exang, sex, slope, thal, thalach и trestbps.
На основании корреляции признаков строим новую модель нейронной сети, в которой коррелирующие признаки связаны с одним и тем же скрытым нейроном. Схема итоговой оптимизированной модели представлена на рисунке 3.
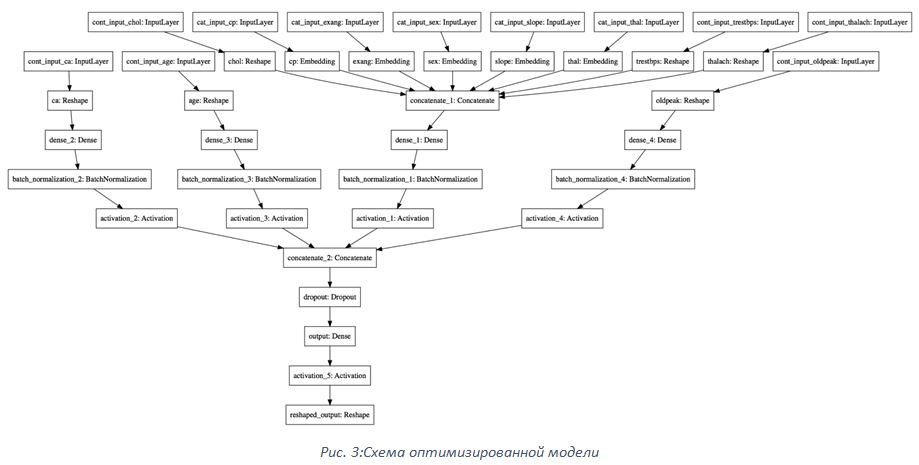
Производительность итоговой модели сравнивалась с классификатором SVM, обычной полносвязной нейронной сетью и наивным Байесовским классификатором.
Задача классификации и регрессии с помощью метода SVM имеет целью разработку алгоритмически эффективных методов построения оптимальной разделяющей гиперплоскости в пространстве признаков высокой размерности [19]. Наивный байесовский классификатор же основан на применении теоремы Байеса со строгими предположениями о независимости входных данных [20].
В качестве критериев оценки производительности, кроме точности, использовались положительное (PPV) и отрицательное предсказывающие значения (NPV). PPV показывает вероятность заболевания при положительном прогнозе, NPV же характеризует вероятность отсутствия заболевания при отрицательном прогнозе.
Таблица 2: Сравнительный анализ методов прогнозирования
|
|
PPV |
NPV |
Точность |
|
Предлагаемая модель |
0,92 |
0,92 |
92,22% |
|
SVM |
0,86 |
0,87 |
86,67 % |
|
Наивный Байесовский классификатор |
0,84 |
0,88 |
86,67 % |
|
Полносвязная нейронная сеть |
0,91 |
0,90 |
91,11 % |
Из таблицы 2 мы видим, что классификатор SVM вместе с наивным Байесовским классификатором показали более слабые результаты, чем нейронная сеть. Предложенная модель выступила лучше обычной нейронной сети, поскольку она удаляет ненужные признаки во время обучения модели. Иными словами, отбор признаков на основе чувствительности может эффективно выявлять признаки, связанные с риском развития ишемической болезни сердца.
В итоге, можно утверждать, что предлагаемая модель очень хороша с точки зрения производительности и эффективна в прогнозировании риска развития ишемической болезни сердца.
Немало исследований проведено для прогнозирования риска ишемической болезни сердца и в большинстве случаев были использованы нейронные сети и линейные регрессоры. Согласно полученным результатам, для создания более эффективных моделей нейронных сетей необходимо учитывать значимость признаков для результатов работы модели и отсеивать незначимые признаки.
Заключение
Предложенная модель нейронной сети с использованием корреляционного анализа признаков показала более высокую точность (92,22%) в прогнозировании риска развития ишемической болезни сердца по сравнению с наивным байесовским классификатором, SVM и полносвязной нейронной сетью и доказала, что может быть более полезной в предварительной диагностике пациентов.
Система медицинского прогнозирования, разработанная в рамках данной работы, имеет большую практическую значимость, поскольку её внедрение может повысить оперативность и точность предварительной диагностики пациентов. Представленный подход к её реализации, основанный на технологиях Keras, pandas и PyQt, имеет значительные преимущества в сравнении с большинством использующихся на настоящий момент разработок. Pandas распространяется под свободной лицензией BSD. Keras распространяется под свободной лицензией MIT. PyQt распространяется под свободной лицензией GPL.
1. http://www.who.int/en/news-room/fact-sheets/detail/the-top-10-causes-of-death - информационный бюллетень о причинах смертности от Всемирной организации здравоохранения (дата последнего обращения: 05.07.2018).
2. Cook, S., Ladich, E., Nakazawa, G. Correlation of intravascular ultrasound findings with histopathological analysis of thrombus aspirates in patients with very late drug-eluting stent thrombosis // Circulation, vol. 120, №5, 2009 - С. 391–399.
3. Bonow, R.O., Carabello, B.A., Chatterjee, K. 2008 Focused update incorporated into the ACC/AHA 2006 guidelines for the management of patients with valvular heart disease: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines (Writing Committee to Revise the 1998 Guidelines for the Management of Patients With Valvular Heart Disease): endorsed by the Society of Cardiovascular Anesthesiologists, Society for Cardiovascular Angiography and Interventions, and Society of Thoracic Surgeons // Journal of the American College of Cardiology, vol. 52, №13, 2008 – С. 1–142.
4. Verma, L., Srivastava, S., Negi, P. C. A hybrid data mining model to predict coronary artery disease cases using noninvasive clinical data // Journal of Medical Systems, vol. 40, №7, 2016 - С. 1–7.
5. Zhao, Z., Ma, C. An intelligent system for noninvasive diagnosis of coronary artery disease with EMD-TEO and BP neural network // 2008 International Workshop on Education Technology and Training & 2008 International Workshop on Geoscience and Remote Sensing, vol. 2, 2008 - С. 631–635.
6. Arabasadi, Z., Alizadehsani, R., Roshanzamir, M., Moosaei, H., Yarifard, A.A. Computer aided decision making for heart disease detection using hybrid neural network-genetic algorithm // Computer Methods and Programs in Biomedicine, vol. 141, 2017 – С. 19–26.
7. Narain, R., Saxena, S., Goyal, A.K. Cardiovascular risk prediction: a comparative study of Framingham and quantum neural network based approach // Patient Preference and Adherence, vol. 10, 2016 – С. 1259–1270.
8. M. Kukar, I. Kononenko, C. Grošelj, K. Kralj, and J. Fettich. Analysing and improving the diagnosis of ischaemic heart disease with machine learning // Artificial Intelligence in Medicine,vol. 16, №1, 1999 – С. 25–50.
9. Sussillo, D., Barak, O. Opening the black box: lowdimensional dynamics in high-dimensional recurrent neural networks // Neural Computation, vol. 25, №3, 2013 - С. 626–649.
10. Семёнов, В.А., Колесников, В.Н. Политический анализ и прогнозирование. Учебное пособие. – СПб.: Питер, 2014. - 432 с.
11. Гудфеллоу, Я., Бенджио, И., Курвилль, А. Глубокое обучение. – М.: ДМК Пресс, 2018. – 654 с.
12. Kingma, P.D., Ba J. Adam: A Method for Stochastic Optimization // arXiv preprint arXiv:1412.6980v9 [cs.LG], 2017 – 15 с.
13. Мартин, Д. Психологические эксперименты. Секреты механизмов психики - СПб.: Прайм-Еврознак, 2005. - 477 с.
14. Плохотников, К.Э., Колков, С.В. Статистика – М.: Флинта, 2010. - 288 с.
15. Kim, J.K., Kang, S. Neural Network-Based Coronary Heart Disease Risk Prediction Using Feature Correlation Analysis // Journal of Healthcare Engineering, vol. 2017, 2017 – 13 с.
16. https://keras.io/ - официальный сайт проекта Keras (дата последнего обращения: 05.07.2018).
17. https://pandas.pydata.org/ - официальный сайт проекта pandas (дата последнего обращения: 05.07.2018).
18. https://archive.ics.uci.edu/ml/datasets/Heart+Disease - свободная база данных результатов обследований пациентов Кливлендской клиники (дата последнего обращения: 05.07.2018).
19. Вьюгин, В.В. Математические основы теории машинного обучения и прогнозирования - М.: 2013. - 387 с.
20. Шолле, Ф. Глубокое обучение на R – СПб.: Питер, 2018. – 400 с.
1. http://www.who.int/en/news-room/fact-sheets/detail/the-top-10-causes-of-death - a fact sheet on the causes of death from the World Health Organization (last access date: 05.07.2018).
2. Cook, S., Ladich, E., Nakazawa, G. Correlation of intravascular ultrasound findings with histopathological analysis of thrombus aspirates in patients with very late drug-eluting stent thrombosis. Circulation, vol. 120, no. 5, 2009 – P. 391–399.
3. Bonow, R.O., Carabello, B.A., Chatterjee, K. 2008 Focused update incorporated into the ACC/AHA 2006 guidelines for the management of patients with valvular heart disease: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines (Writing Committee to Revise the 1998 Guidelines for the Management of Patients With Valvular Heart Disease): endorsed by the Society of Cardiovascular Anesthesiologists, Society for Cardiovascular Angiography and Interventions, and Society of Thoracic Surgeons. Journal of the American College of Cardiology, vol. 52, no. 13, 2008 – P. 1–142.
4. Verma, L., Srivastava, S., Negi, P. C. A hybrid data mining model to predict coronary artery disease cases using noninvasive clinical data. Journal of Medical Systems, vol. 40, no. 7, 2016 - P. 1–7.
5. Zhao, Z., Ma, C. An intelligent system for noninvasive diagnosis of coronary artery disease with EMD-TEO and BP neural network. 2008 International Workshop on Education Technology and Training & 2008 International Workshop on Geoscience and Remote Sensing, vol. 2, 2008 – P. 631–635.
6. Arabasadi, Z., Alizadehsani, R., Roshanzamir, M., Moosaei, H., Yarifard, A.A. Computer aided decision making for heart disease detection using hybrid neural network-genetic algorithm. Computer Methods and Programs in Biomedicine, vol. 141, 2017 – P. 19–26.
7. Narain, R., Saxena, S., Goyal, A.K. Cardiovascular risk prediction: a comparative study of Framingham and quantum neural network based approach. Patient Preference and Adherence, vol. 10, 2016 – P. 1259–1270.
8. M. Kukar, I. Kononenko, C. Grošelj, K. Kralj, and J. Fettich. Analysing and improving the diagnosis of ischaemic heart disease with machine learning. Artificial Intelligence in Medicine,vol. 16, no. 1, 1999 – P. 25–50.
9. Sussillo, D., Barak, O. Opening the black box: lowdimensional dynamics in high-dimensional recurrent neural networks. Neural Computation, vol. 25, no. 3, 2013 - P. 626–649.
10. Semenov, V.A., Kolesnikov, V.N. Politicheskiy analiz i prognozirovanie. Uchebnoe posobie. – SPb.: Piter, 2014. - 432p.
11. Gudfellou, Ya., Bendzhio, I., Kurvill', A. Glubokoe obuchenie. – M.: DMK Press, 2018. – 654p.
12. Kingma, P.D., Ba J. Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980v9 [cs.LG], 2017 – 15p.
13. Martin, D. Psikhologicheskie eksperimenty. Sekrety mekhanizmov psikhiki - SPb.: Praym-Evroznak, 2005. - 477p.
14. Plokhotnikov, K.E., Kolkov, S.V. Statistika – M.: Flinta, 2010. - 288p.
15. Kim, J.K., Kang, S. Neural Network-Based Coronary Heart Disease Risk Prediction Using Feature Correlation Analysis. Journal of Healthcare Engineering, vol. 2017, 2017 – 13p.
16. https://keras.io/ - official site of Keras project (last access date: 05.07.2018).
17. https://pandas.pydata.org/ - official site of pandas project (last access date: 05.07.2018).
18. https://archive.ics.uci.edu/ml/datasets/Heart+Disease – a free database of the results of patient surveys at the Cleveland Clinic Foundation (last access date: 05.07.2018).
19. V'yugin, V.V. Matematicheskie osnovy teorii mashinnogo obucheniya i prognozirovaniya - M.: 2013. - 387p.
20. Sholle, F. Glubokoe obuchenie na R – SPb.: Piter, 2018. – 400p.
архив: 2013 2012 2011 1999-2011 новости ИТ гость портала 2013 тема недели 2013 поздравления
E-mail редакции: vzh85@yandex.ru, 